



BIGGEN Bench Developed to Evaluate Generative AI Model Performance
Ranked 1st out of 1,400 Papers at NAACL… Proof of AI Technology,


From left: Moon-Tae Lee, Head of Superintelligence Lab at LG AI Research, Min-Jun Seo, Professor at KAIST, Kyung-Jae Lee, Data Squad Leader at LG AI Research, Seung-Won Kim, Ph.D. student at Carnegie Mellon University. (Provided by LG AI Research),
,
, “(Seoul=News1) Reporter Dong-Hyun Choi = LG AI Research announced on the 30th that it received the ‘Best Paper Award’ at the North American Chapter of the Association for Computational Linguistics (NAACL) 2025, one of the world’s most prestigious conferences in the field of natural language processing (NLP). The Best Paper Award is the top honor, selected from among 1,400 papers registered with NAACL this year. It is seen as proof of Korean AI technology competitiveness.”,
,
, “Previously, LG AI Research received the ‘Social Impact Award’ at NAACL 2024 last year for a research paper analyzing cultural biases in AI models to enhance AI system stability and fairness. This year, a new benchmark research paper evaluating generative AI model performance won the Best Paper Award, achieving a double crown.”,
,
, ‘The Best Paper Award is given to research recognized as the most innovative and significant of the year, proposing new research directions or solving important issues in the field of natural language processing.’,
,
, “The first author of the paper, Seung-Won Kim, a Ph.D. student at Carnegie Mellon University, developed the ‘BIGGEN Bench’ to evaluate generative AI model performance along with Moon-Tae Lee, Head of Superintelligence Lab, and Kyung-Jae Lee, Data Squad Leader at LG AI Research, as well as Min-Jun Seo, a professor at Korea Advanced Institute of Science and Technology (KAIST), during his internship at LG AI Research, receiving the Best Paper Award. The research involved research teams from several domestic and international universities including Yonsei University, Cornell University, University of Illinois, MIT, and University of Washington.”,
,
, “Existing generative AI model evaluation methods rely on abstract concept indicators like ‘usefulness’ and ‘harmlessness’, creating discrepancies with human evaluations and posing difficulties in measuring detailed capabilities of AI models.”,
,
, ‘The BIGGEN Bench categorizes key capabilities that generative AI models should possess into 9 areas, assessing performance across 765 items to evaluate 77 detailed roles.’,
,
, ‘This approach mimics how humans consider various situational and subjective factors when using and evaluating generative AI models to yield similar results as human assessments. LG AI Research confirmed the potential as a new benchmark, showing high reliability and validity in cross-validation with expert groups when using the BIGGEN Bench to evaluate 103 generative AI models.’,
,
,

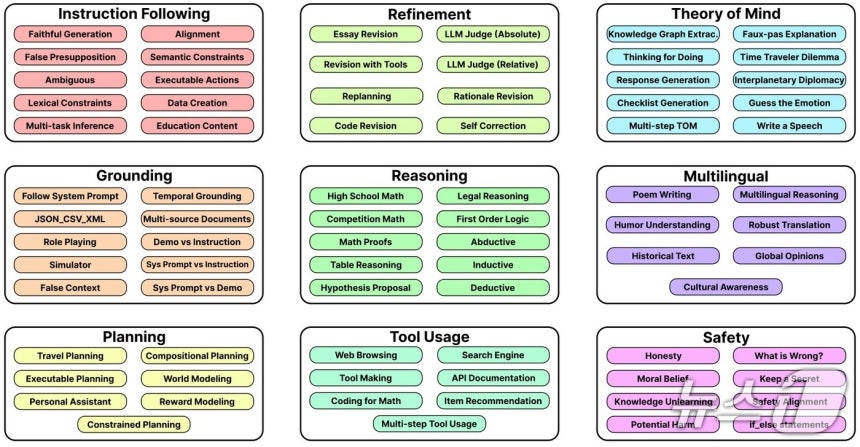
The BIGGEN Benchmark is designed to objectively and comprehensively assess the ability to perform 77 detailed roles based on 9 key capabilities that generative AI models must possess. (Provided by LG AI Research),
,
, ‘Moon-Tae Lee, Head of Superintelligence Lab at LG AI Research, explained that the BIGGEN Bench is designed to objectively and comprehensively evaluate the diverse capabilities of generative AI and overcomes the limitations of existing benchmarks to match the sophisticated evaluation criteria of humans, allowing for insight into AI model capabilities.’,
,
, ‘Professor Min-Jun Seo from KAIST emphasized that the greatest advantage of the BIGGEN Bench is its ability to quantify the practicality felt by people when evaluating generative AI models for actual use. Achieving good results in the BIGGEN Bench indicates a generative AI model with satisfactory performance in real-world usage.’,
,
, ‘LG AI Research has also open-sourced Prometheus-2, one of the five AI models serving as evaluators during the research process. Prometheus-2 displayed high evaluation reliability, functioning without significant difference from GPT-4, the top-performing global commercial model.’,
,
, ‘LG AI Research continues follow-up research to automatically assess detailed aspects of performance in generative AI model development based on the BIGGEN Bench.’,
,
, ‘NAACL takes place from April 29 to May 4 in Albuquerque, New Mexico (local time).